本文正在参与 “网络协议必知必会”征文活动
HTTP协议各版本介绍
HTTP协议是如今互联网与服务端技术的基石,HTTP协议的演进也从侧面反应了互联网技术的快速发展。这两天在准备一次关于HTTP1.1协议特性的技术分享过程中,顺便了解了下各版本HTTP协议的特点,在这里做个简单的总结。
HTTP协议到现在为止总共经历了3个版本的演化,第一个HTTP协议诞生于1989年3月。

HTTP 0.9
HTTP 0.9是第一个版本的HTTP协议,已过时。
它的组成极其简单,只允许客户端发送GET这一种请求,且不支持请求头。
由于没有协议头,造成了HTTP 0.9协议只支持一种内容,即纯文本。不过网页仍然支持用HTML语言格式化,同时无法插入图片。
HTTP 0.9具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。
一次HTTP 0.9的传输首先要建立一个由客户端到Web服务器的TCP连接,由客户端发起一个请求,然后由Web服务器返回页面内容,然后连接会关闭。如果请求的页面不存在,也不会返回任何错误码。
HTTP 1.0
HTTP协议的第二个版本,第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用。相对于HTTP 0.9 增加了如下主要特性:
- 请求与响应支持头域
- 响应对象以一个响应状态行开始
- 响应对象不只限于超文本
- 开始支持客户端通过POST方法向Web服务器提交数据,支持GET、HEAD、POST方法
- 支持长连接(但默认还是使用短连接),缓存机制,以及身份认证
HTTP 1.1
HTTP协议的第三个版本是HTTP 1.1,是目前使用最广泛的协议版本 。HTTP 1.1是目前主流的HTTP协议版本。
HTTP 1.1引入了许多关键性能优化:keepalive连接,chunked编码传输,字节范围请求,请求流水线等
- Persistent Connection(keepalive连接)
允许HTTP设备在事务处理结束之后将TCP连接保持在打开的状态,一遍未来的HTTP请求重用现在的连接,直到客户端或服务器端决定将其关闭为止。
在HTTP1.0中使用长连接需要添加请求头 Connection: Keep-Alive,而在HTTP 1.1 所有的连接默认都是长连接,除非特殊声明不支持( HTTP请求报文首部加上Connection: close )
1 | less复制代码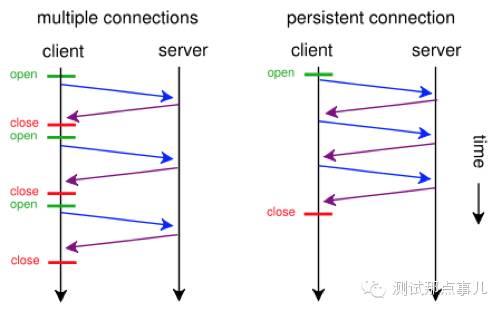 |
- chunked编码传输
该编码将实体分块传送并逐块标明长度,直到长度为0块表示传输结束, 这在实体长度未知时特别有用(比如由数据库动态产生的数据) - 字节范围请求
HTTP1.1支持传送内容的一部分。比方说,当客户端已经有内容的一部分,为了节省带宽,可以只向服务器请求一部分。该功能通过在请求消息中引入了range头域来实现,它允许只请求资源的某个部分。在响应消息中Content-Range头域声明了返回的这部分对象的偏移值和长度。如果服务器相应地返回了对象所请求范围的内容,则响应码206(Partial Content) - Pipelining(请求流水线)
1 | bash复制代码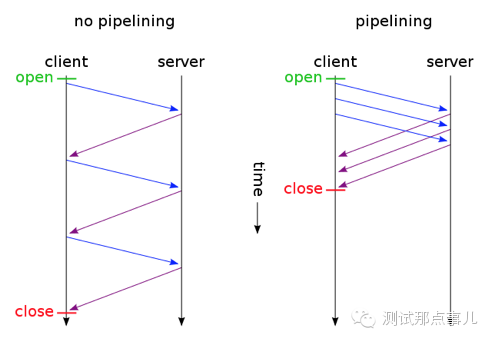 |
另外,HTTP 1.1还新增了如下特性:
- 请求消息和响应消息都应支持Host头域
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。因此,Host头的引入就很有必要了。 - 新增了一批Request method
HTTP1.1增加了OPTIONS,PUT, DELETE, TRACE, CONNECT方法 - 缓存处理
HTTP/1.1在1.0的基础上加入了一些cache的新特性,引入了实体标签,一般被称为e-tags,新增更为强大的Cache-Control头。
HTTP 2.0
HTTP 2.0是下一代HTTP协议,目前应用还非常少。主要特点有:
为了解决1.1版本利用率不高的问题,提出了HTTP/2.0版本。增加双工模式,即不仅客户端能够同时发送多个请求,服务端也能同时处理多个请求,解决了队头堵塞的问题(HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级)。
HTTP请求和响应中,状态行和请求/响应头都是些信息字段,并没有真正的数据,因此在2.0版本中将所有的信息字段建立一张表,为表中的每个字段建立索引,客户端和服务端共同使用这个表,他们之间就以索引号来表示信息字段,这样就避免了1.0旧版本的重复繁琐的字段,并以压缩的方式传输,提高利用率。
- 多路复用(二进制分帧)
HTTP 2.0最大的特点: 不会改动HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念上一如往常,却能致力于突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。而之所以叫2.0,是在于新增的二进制分帧层。在二进制分帧层上, HTTP 2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。
HTTP 2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。 - 头部压缩
当一个客户端向相同服务器请求许多资源时,像来自同一个网页的图像,将会有大量的请求看上去几乎同样的,这就需要压缩技术对付这种几乎相同的信息。 - 随时复位
HTTP1.1一个缺点是当HTTP信息有一定长度大小数据传输时,你不能方便地随时停止它,中断TCP连接的代价是昂贵的。使用HTTP2的RST_STREAM将能方便停止一个信息传输,启动新的信息,在不中断连接的情况下提高带宽利用效率。 - 服务器端推流: Server Push
客户端请求一个资源X,服务器端判断也许客户端还需要资源Z,在无需事先询问客户端情况下将资源Z推送到客户端,客户端接受到后,可以缓存起来以备后用。 - 优先权和依赖
每个流都有自己的优先级别,会表明哪个流是最重要的,客户端会指定哪个流是最重要的,有一些依赖参数,这样一个流可以依赖另外一个流。优先级别可以在运行时动态改变,当用户滚动页面时,可以告诉浏览器哪个图像是最重要的,你也可以在一组流中进行优先筛选,能够突然抓住重点流。

结语
文章首发于微信公众号程序媛小庄,同步于掘金。
码字不易,转载请说明出处,走过路过的小伙伴们伸出可爱的小指头点个赞再走吧(╹▽╹)
本文转载自: 掘金
 image-20210923080715957
image-20210923080715957  image-20210923080753902
image-20210923080753902  image-20210923080632563
image-20210923080632563  image-20210923082936339
image-20210923082936339  image-20210923084747640
image-20210923084747640  image-20210923094800813
image-20210923094800813  image-20210923101309076
image-20210923101309076  image-20210923101705704
image-20210923101705704  image-20210820161809631
image-20210820161809631  image-20210821215721123
image-20210821215721123  image-20210821220245289
image-20210821220245289  image-20210821225646389
image-20210821225646389  image-20210821231545236
image-20210821231545236  image-20210821231946026
image-20210821231946026  image-20210821232916290
image-20210821232916290  image-20210912150415470
image-20210912150415470  image-20210912174618496
image-20210912174618496  image-20210912175703527
image-20210912175703527  image-20210912201352859
image-20210912201352859  image-20210912195704561
image-20210912195704561  image-20210912200345318
image-20210912200345318  image-20210912210111460
image-20210912210111460  image-20210912210718304
image-20210912210718304  image-20210912212544483
image-20210912212544483  image-20210912215713723
image-20210912215713723  image-20210912224129279
image-20210912224129279  image-20210913005714774
image-20210913005714774  image-20210913012002615
image-20210913012002615  image-20210912222610487
image-20210912222610487  image-20210912233051911
image-20210912233051911  image-20210912233234287
image-20210912233234287 







